What is the TSP(Traveling Salesman Problem)?
Cheapest Insertion (最少代价插入)(DP | Greedy Approach)
Farthest Insertion (最远插入法)(DP | Greedy Approach)
Why should I use OpenMp
-
We can achieve some pretty good speed up with normal hardware
-
Thread based parallelism
-
Targeted at share memory
-
Uses work sharing and tasks
| Process | Thread |
|---|---|
| A basic unit of work for the operating system | Part of a program that can be run independently to other portions |
| Big overheads in creating/detention/context switching | Small overheads in comparison |
| isolate from other processes | Shared memory with other threads in the same process egfiles |
| Share heap |
How do I use OpenMP
The fork-join model
- Expressions
| expression | description |
|---|---|
| #pragma omp parallel | |
| #pragma omp for | if the data is independent you can use data parallelism |
| #pragma omp parallel shared(i) | shared access acriss akk threads |
| #pragma omp parallel private(i) | Each thread gets it own copy of the variable |
| #pragma omp parallel firstprivate(i) | |
| #pragma omp parallel lastprivate(i) | |
| #pragma omp parallel for default(shared) | |
| #pragma omp parallel for reduction(+, sum) | performs some operation with the results |
| #pragma omp parallel schedule<sraruc/dynamic, |
|
| collapse | |
| reduction |
| schuduleing | | | locking | |
- To define how threads to use our program
- export OMP_NUM_THREADS = 8; ./a.out
- #pragma omp parallel num_threads(x)
- omp_set_num_threads(x)
Scheduleing parallel for static/dynamic/guided
-
If we have four threads and use static scheduling we get this, notice it isn’t even
-
If we use dynamic then once a thread has finished its work it will take another job
-
schedule(guided,
) - Chunks of decreasing size are handed out, it’s a dynamic variant -
schedule(runtime) - You can pass the schedule as an environment variable using OMP_SCHEDULE
-
schedule(auto) - The scheduler learns the problem after a few runs, don’t use this one
Locking Manual locks
Low level lock
-
omp_lock_t - This is the data type of a variable lock
-
omp_init_lock - This initialises the lock variable and sets it’s value to ‘unlocked’, meaning any thread reaching that point doesn’t have to stop
-
omp_set_lock - Once a thread passes this point, all other threads reaching this point have to wait until it unlocks
-
omp_unset_lock - Unlocks the variable lock
High level lock
-
We can use
#pragma omp critical, this creates a lock for that portion of the code -
Only one thread at a time can run that portion of code
-
The solution is
#pragma omp atomic -
It has hardware support, but it’s far less flexible than #pragma omp critical
-
#pragma omp atomic write- This allows for a statement to receive exclusive write access, still allows for the variables to be read
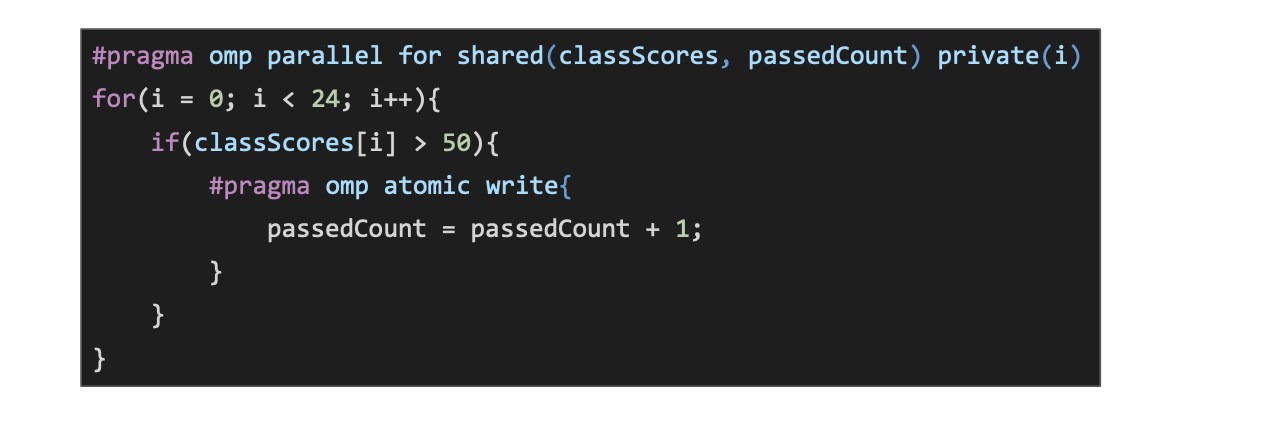
#pragma omp atomic read- This temporarily locks a variable so it can only be read to, avoids reading intermediate values
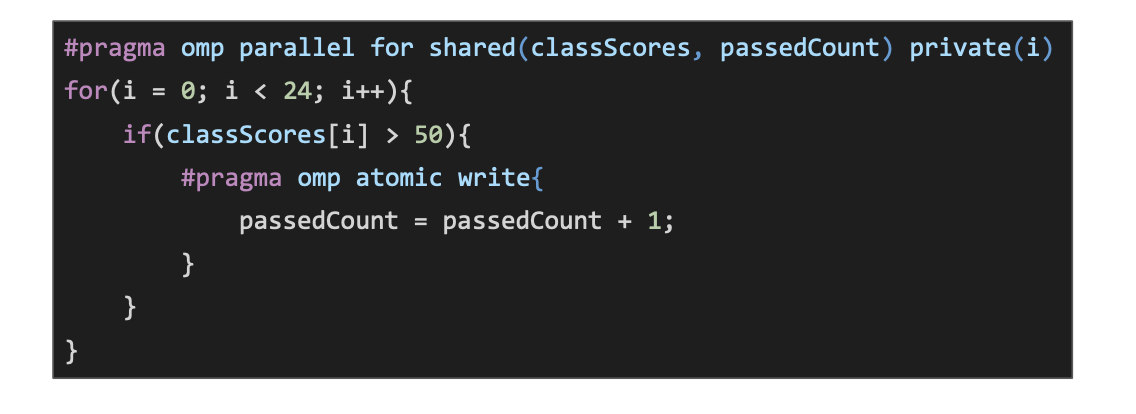
#pragma omp atomic update- This creates a lock for writing when another thread is writing, and a lock for reading when another thread is reading

#pragma omp atomic capture- This is a complete lock, similar to a critical region, however this requires hardware support for this feature. If the support doesn’t exist then it default to a critical region, which has some additional overhead

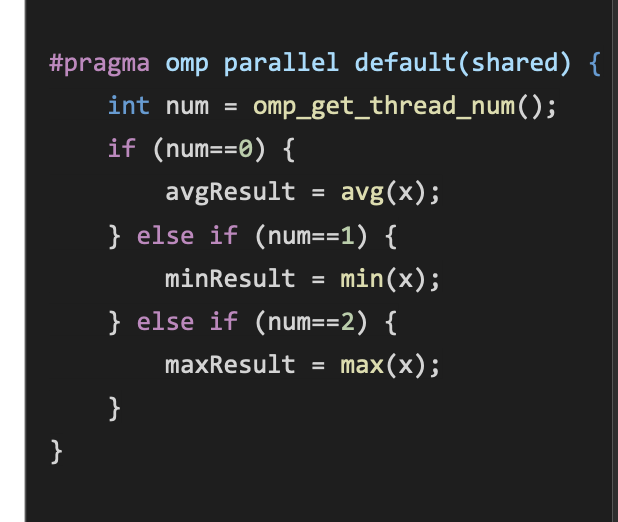
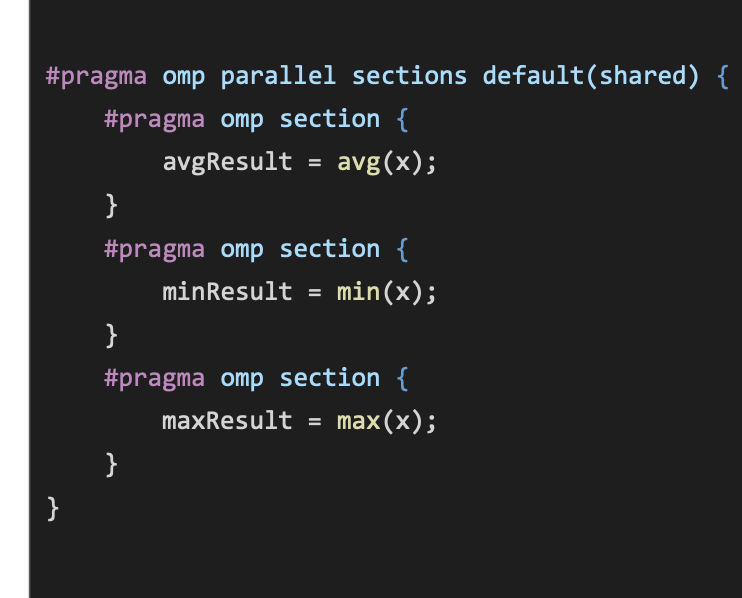
Sections
#pragma omp section - Defines some work that only needs to be carried out by a single thread
- Makes the code more readable
- You’re not keeping track of the thread number
- Number of usable threads is limited by the number of sections
Expect:
Partical:
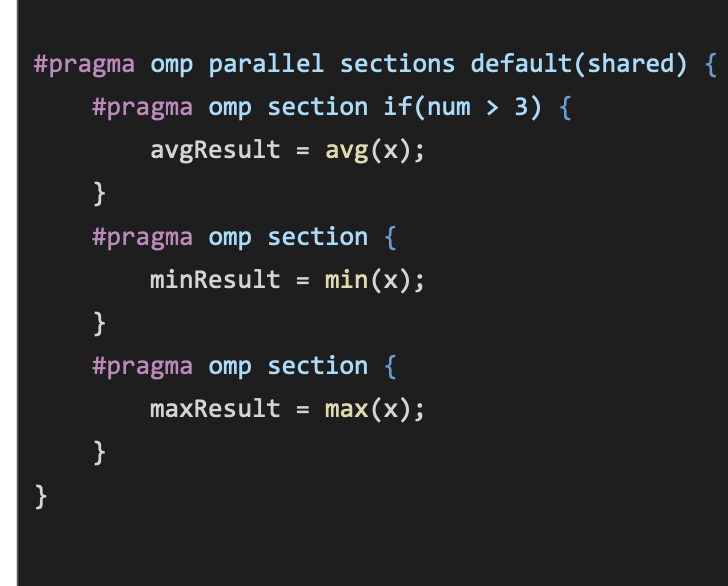
If clause
- Sometimes you’ll want something to execute if a particular condition is met
- if(x) - Allows you to put a condition on the execution of some parallel code
- This is only an if, not an if else
- I think it’s kinda cool, but i’ve never found a good use for it
Timing
I’ve mentioned before that there are multiple ways to time things in C The best method while using OpenMP is to use omp_get_wtime() You don’t have to worry about clock cycles etc

Deadlocks
-
Low level locks don’t always cause deadlocks, it’s just more likely to program it poorly
We need four things:
- Initialise the lock
- Set the lock
- Unset the lock
- Destroy the lock
Critical and Atomic
Critical
- Can cover multiple statements
- Is generalised so you can carry out any operation inside, read or write
Atomic
- Only allows a single statement
- Is usually specialised to lock one particular type of operation
Difference
- Explicit workload balancing: We define exactly what each thread should do
- Implicit workload balancing - We let the software sort out what each thread does
The fork-joint model
Environmental variables
- OMP_PROC_BIND - Whichever core you execute a thread on, keep it where it is (choose it randomly, but do not move)
- OMP_SET_DYNAMIC - OpenMP views your num_threads etc as guidelines, you can make it listen to you by disabling this
- OMP_PLACES - Lets to hand pick which thread lives on which core, this is very fiddly, probably avoid this
Barriers
-
#pragma omp barrier- That’s it, you don’t need any code underneath it. Really handy if you need to do something that isn’t thread safe like file loading -
#pragma omp single- Runs on a single thread, then has an implicit barrier. It has an implicit barrier at the end, so the other threads carry on when it’s done Really handy if you need to do something that isn’t thread safe like file loading.
Master
Using the master thread is good if you just need one thread to execute something but don’t care about being thread safe
- Lower overhead than single
- Can be placed inside of a workshare construct like parallel for
Tasks
- #pragma omp tasks - A task unit that is executed by each thread
Non-Uniform Memory Access (NUMA)
Non-Uniform Memory Access: Each CPU has the L1, and L2 registers, but shares an L3 register
-
Spatial locality - if memory is accessed then it’s neighbours are likely to be accessed next (move data as a block, not as it’s needed)
-
Temporal locality - if a variable is used, it is likely to be needed again soon (keep it in the cache)
Memory assignment
An array may not be stored in one continuous position in memory, it could be split across several different areas
-
The array which we access as if it’s all in one memory location, is actually split across CPUs


False sharing
The OS doesn’t have any idea what we are doing, so it gives a copy of the sum_local cache to each of the threads
Vector units
Padding
We can add additional empty elements to an array, this is called padding